Flume -NG
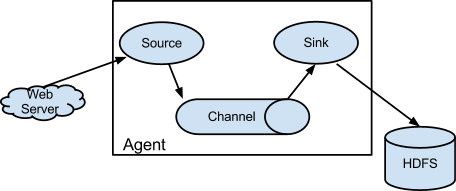
* Event : flume에서 전달하는 데이터 단위
* Source
- 웹 서버 같은 외부 소스에 의해 전달되는 이벤트 수집
- 외부 소스는 Flume이 인식하는 형태로 이벤트를 전달
* Channel
- 소스가 이벤트를 수신하면 채널에 임시 저장
- 채널은 싱크가 이벤트를 다른 목적지로 전달할 때까지 파일이나 메모리 등에 이벤트를 보관
* Sink
- 채널에 저장된 이벤트를 외부 저장소, 다른 flume agent로 전달
- 소스와 싱크는 비동기적으로 진행
Flume workflow

1. Config
- Fulme 작업 파일을 읽고 channel, source, sink를 설정함
- 내부적으로 30초마다 Configuration 파일 로드함. Flume 재시작하지 않아도 workflow 재설정 가능
2. Source
- config가 로드되면, source runner 수행하여 데이터를 channel로 전송
- source에서 event 생성되면, 설정된 channel 목록 가져와서 해당 channel에 event 할당
- 생성된 event를 channel로 전송, sink 프로세스에서 가져갈 수 있도록 함
3. Channel
- event transaction 관리, event를 queue에 저장
- source에서 보낸 putlist와 sink에서 가져간 takelist를 통해 transaction 관리
4. Sink
- 설정된 목록 내에서 channel들의 queue에서 메시지를 꺼내서 처리
1. Apache Flume 설치
Mirror Site에서 bigpi1으로 설치 파일 다운 받으면 된다.

버전은 1.9.0이며, apache-flume-1.9.0-bin.tar.gz를 다운 받으면 된다.

$ wget mirror.navercorp.com/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
flume 설치 파일 압축 해제 및 설정

$ sudo tar -xvf apache-flume-1.9.0-bin.tar.gz -C /opt/
$ rm apache-flume-1.9.0-bin.tar.gz
$ cd /opt
$ sudo mv apache-flume-1.9.0-bin flume
$ sudo chown pi:pi -R /opt/flume
~/.bashrc 파일에 관련된 환경변수 추가
$ cd ~
$ nano .bashrc
$ source .bashrc

(...생략...)
export SPARK_HOME=/opt/spark
export FLUME_HOME=/opt/flume # 추가
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$FLUME_HOME/bin # 수정
(...생략...)
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export FLUME_CONF_DIR=/opt/flume/conf # 추가
(...생략...)
/opt/flume/conf/flume-env.sh 파일에 JAVA_HOME 경로 지정

$ cd /opt/flume/conf
$ sudo cp flume-env.sh.template flume-env.sh
$ sudo nano flume-env.sh

export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
샘플 workflow 실행
$ sudo cp flume-conf.properties.template flume-conf.properties
$ cat flume-conf.properties

# agent라는 이름의 workflow에 대해서 source, channel, sink 나열
# seqGenSrc라는 source의 타입을 지정
# seqGenSrc가 사용할 channel의 이름 지정
# loggerSink라는 sink의 타입 지정
# loggerSink가 사용할 channel 이름 지정
# memoryChannel의 타입 지정
# momoryChannel의 추가적인 옵션 지정(내부적 저장 가능한 event 크기)
$ flume-ng agent -c /opt/flume/conf --conf-file /opt/flume/conf/flume-conf.properties --name agent -Dflume.root.logger=INFO,console
2. 다양한 workflow 실행
Exec 타입의 source를 이용한 log in 모니터링
* Source(Exec) -> Channel(memory) -> Sink(logger)
flume-exec.properties 새로 작성
$ sudo nano flume-exec.properties
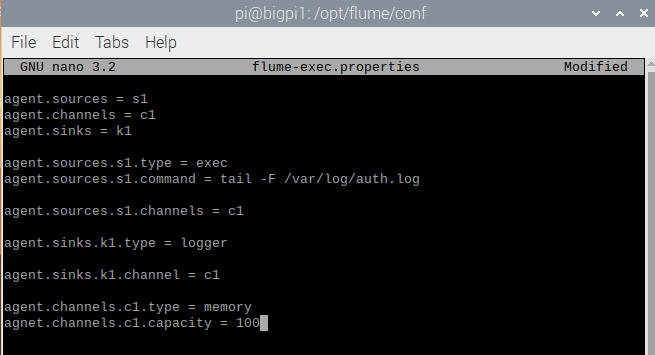
agent.sources = s1
agent.channels = c1
agent.sinks = k1
agent.sources.s1.type = exec
agent.sources.s1.command = tail –F /var/log/auth.log
agent.sources.s1.channels = c1
agent.sinks.k1.type = logger
agent.sinks.k1.channel = c1
agent.channels.c1.type = memory
agent.channels.c1.capacity = 100
bigpi1에서 flume 실행
$ flume-ng agent –c /opt/flume/conf --conf-file /opt/flume/conf/flumeexec.properties
--name agent –Dflume.root.logger=INFO,console
bigpi2에서 terminal 창 열고 bigpi1에 ssh 접속 시도
$ x=0; while [ $x –le 100 ]; do ssh bigpi1 hostname; x=$((x+1)) ; done

접속됨
Multi-hop agent
* 두 개의 agent를 Avro sink와 Avro source로 연결
* bigpi2에서 bigpi1에 계속 로그인을 시도하고, bigpi1은 이러한 로그인으로 인한 /var/log/auth.log 파일의 변경을 bigpi2로
2-tier의 flume agent를 통해 전달함
bigpi1에 설치된 flume을 나머지 cluster에 복사
$ cluster_run sudo mkdir –p /opt/flume
$ cluster_run sudo chown pi:pi –R /opt/flume
$ for x in $(others); do rsync –avxP $FLUME_HOME $x:/opt; done
$ cluster_scp ~/.bashrc
bigpi2, bigpi3, bigpi4에서 변경된 .bashrc 파일 각각 적용
$ source .bashrc
bigpi1에서 flume-multi1.properties 파일 작성
$ sudo nano /opt/flume/conf/flume-multi1.properties

agent.sources = s1
agent.channels = c1
agent.sinks = k1
agent.sources.s1.type = exec
agent.sources.s1.command = tail –F /var/log/auth.log
agent.sources.s1.channels = c1
agent.sinks.k1.type = avro
agent.sinks.k1.hostname = 10.0.2.102
agent.sinks.k1.port = 10000
agent.sinks.k1.channel = c1
agent.channels.c1.type = memory
agent.channels.c1.capacity = 100
bigpi3에서 flume-multi2.properties 파일 작성
$ sudo nano /opt/flume/conf/flume-multi2.properties

agent.sources = s2
agent.channels = c2
agent.sinks = k2
agent.sources.s2.type = avro
agent.sources.s2.port = 10000
agent.sources.s2.bind = 10.0.2.102
agent.sources.s2.channels = c2
agent.sinks.k2.type = logger
agent.sinks.k2.channel = c2
agent.channels.c2.type = memory
agent.channels.c2.capacity = 100
Avro server가 되는 bigpi3의 agent 먼저 실행
$ flume-ng agent –c /opt/flume/conf --conf-file /opt/flume/conf/flumemulti2.properties
--name agent –Dflume.root.logger=INFO,console
Avro client가 되는 bigpi1의 agnet 실행
$ flume-ng agent –c /opt/flume/conf --conf-file /opt/flume/conf/flumemulti1.properties
--name agent –Dflume.root.logger=INFO,console
bigpi2의 terminal 창에서 bigpi1에 ssh 접속 시도
$ x=0; while [ $x –le 100 ]; do ssh bigpi1 hostname; x=$((x+1)) ; done

접속됨
Flume과 Hadoop의 연결
* exec source 통해 log-in 정보를 HDFS sink와 Logger sink로 전달
* Logger sink는 처리내역을 console 창에 확인하기 위한 용도
* HDFS sink를 통해 Hadoop에 log-in 정보를 저장
bigpi1의 /opt/flume/conf/ 에 flume-hdfs.properties 파일 작성
$ sudo nano flume-hdfs.properties

agent.sources = s1
agent.channels = c1
agent.sinks = k1 k2
agent.sources.s1.type = exec
agent.sources.s1.command = tail –F /var/log/auth.log
agent.sources.s1.channels = c1
agent.sinks.k1.type = logger
agent.sinks.k1.channel = c1
agent.sinks.k2.type = hdfs
agent.sinks.k2.channel = c1
agent.sinks.k2.hdfs.path = hdfs://bigpi1:9000/flume/events/%y-%m-%d/%H%M/
agent.sinks.k2.hdfs.writeFormat = Text
agent.channels.c1.type = memory
agent.channels.c1.capacity = 100
bigpi1에서 Hadoop 서비스 시작
$ start-dfs.sh & start-yarn.sh
bigpi1에서 flume agent 실행
$ flume-ng agent –c /opt/flume/conf --conf-file /opt/flume/conf/flumehdfs.properties
--name agent –Dflume.root.logger=INFO,console

timestamp 오류 발생
flume-hdfs.properties 파일에 timestamp 위한 interceptor 추가

agent.sources = s1
agent.channels = c1
agent.sinks = k1 k2
agent.sources.s1.type = exec
agent.sources.s1.command = tail –F /var/log/auth.log
agent.sources.s1.channels = c1
# 여기서부터
agent.sources.s1.interceptors = i1
agent.sources.s1.interceptors.i1.type = timestamp
# 여기까지 추가
(...생략...)
agent.channels.c1.type = memory
agent.channels.c1.capacity = 100
bigpi1의 flume agent 재실행
$ flume-ng agent –c /opt/flume/conf --conf-file /opt/flume/conf/flumehdfs.properties
--name agent –Dflume.root.logger=INFO,console

Guava 라이브러리 버전 불일치로 오류 발생
/opt/flume/lib/fuava-11.0.2.jar 파일 사용 막기

$ cd /opt/flume/lib
$ sudo mv guava-11.0.2.jar guava-11.0.2.jar.backup
hadoop이 사용하는 guava 버전을 flume이 사용하도록 대체
$ sudo cp /opt/hadoop/share/hadoop/hdfs/lib/guava-27.0-jre.jar ./
flume-agent 재실행
$ cd /opt/flume/conf
$ • flume-ng agent –c /opt/flume/conf --conf-file /opt/flume/conf/flumehdfs.properties
--name agent –Dflume.root.logger=INFO,console
bigpi2에서 클러스터의 HDFS에 저장 위한 폴더와 파일 존재하는 것 확인
$ hadoop fs -ls /flume/events

bigpi2에서 login 스크립트 실행하고, bigpi1에서 agent 동작 확인
$ x=0; while [ $x –le 100 ]; do ssh bigpi1 hostname; x=$((x+1)) ; done
HDFS에 login event들 파일로 저장되어 있는 거 확인

$ hadoop fs -cat /flume/events/yy-mm-dd/HHMM/*
나머지 bigpi2, bigpi3, bigpi4에 flume 변경사항 동일하게 반영
$ cd/opt/flume/lib
$ sudo mv guava-11.0.2.jar guava-11.0.2.jar.backup
$ sudo cp /opt/hadoop/share/hadoop/hdfs/lib/guava-27.0-jre.jar ./
'HDFS' 카테고리의 다른 글
| Sqoop (0) | 2021.12.22 |
|---|---|
| HDFS Cluster 설정 (0) | 2021.12.20 |
| Single Node 설정 (2) | 2021.12.20 |
| Cluster 설정 (0) | 2021.12.16 |
| 가상환경 설치(virtual hadoop cluster 구성) (0) | 2021.12.16 |



