1. Hadoop 파일 복사 디렉터리 구성
cluster 구성 위해 master 뿐 아니라 worker node에 hadoop 파일 복사 및 설정 필요
- master : bigpi1
- worker node : bigpi2, bigpi3, bigpi4
clutser 내의 다른 서버에 관련 디렉터리 생성 및 권한 설정
$ cluster_run sudo mkdir –p /opt/hadoop_tmp/hdfs
$ cluster_run sudo chown pi:pi –R /opt/hadoop_tmp
$ cluster_run sudo mkdir –p /opt/hadoop
$ cluster_run sudo chown pi:pi –R /opt/hadoop
bigpi1에서 /opt/hadoop 내의 모든 파일들을 다른 서버에 복사
$ for x in $(others); do rsync -avxP $HADOOP_HOME $x:/opt; done
bigpi1의 .bashrc 파일을 다른 서버에 전달한 후 전체 reboot
$ cluster_scp ~/.bashrc
$ cluster_reboot
각각의 서버에서 hadoop version 확인

$ hadoop version
2. HDFS 설정 및 실행
/opt/hadoop/etc/hadoop 디렉터리 하위에 설정 파일들 수정
[core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml]
core-site.xml 파일 수정
$ sudo nano /opt/hadoop/etc/hadoop/core-site.xml

<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://bigpi1:9000</value>
</property>
</configuration>
hdfs-site.xml 파일 수정
$ sudo nano /opt/hadoop/etc/hadoop/hdfs-site.xml

<cofiguration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop_tmp/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop_tmp/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
mapred-site.xml 파일 수정
$ sudo nano /opt/hadoop/etc/hadoop/mapred-site.xml

<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
# 아래 내용 추가
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>128</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>128</value>
</property>
</configuration>
yarn-site.xml 파일 수정
$ sudo nano /opt/hadoop/etc/hadoop/yarn-site.xml
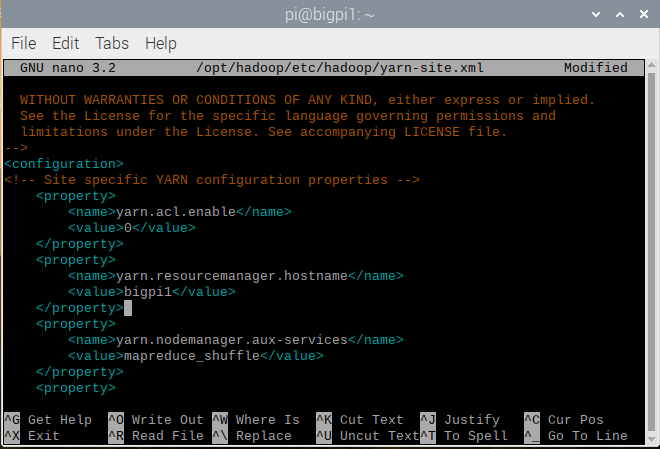
<configuration>
# 여기부터
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigpi1</value>
</property>
# 여기까지 추가
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>

# 맨 하단에 추가
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>900</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>900</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>64</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
다른 서버에 모든 설정 파일 복사

$ cluster_scp /opt/hadoop/etc/hadoop/core-site.xml
$ cluster_scp /opt/hadoop/etc/hadoop/hdfs-site.xml
$ cluster_scp /opt/hadoop/etc/hadoop/mapred-site.xml
$ cluster_scp /opt/hadoop/etc/hadoop/yarn-site.xml
기존 datanode와 namenode 디렉터리 하위 모든 파일 삭제
$ cluster_run rm -rf /opt/hadoop_tmp/hdfs/datanode/*
$ cluster_run rm -rf /opt/hadoop_tmp/hdfs/namenode/*
/opt/hadoop/etc/hadoop/ 디렉터리 하위에 master 파일 생성
$ nano /opt/hadoop/etc/hadoop/master

bigpi1 추가
/opt/hadoop/etc/hadoop/ 디렉터리 하위에 workers 파일 수정
$ nano /opt/hadoop/etc/hadoop/workers
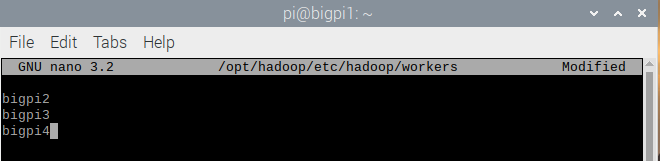
master 와 workers 파일 전체 서버에 복사

$ cluster_scp /opt/hadoop/etc/hadoop/master
$ cluster_scp /opt/hadoop/etc/hadoop/workers
/etc/hosts 파일 수정

127.0.1.1 bigpi1 줄 삭제
/etc/hosts 파일 전체 서버에 복사 후 cluster 전체 reboot

$ cluster_scp /etc/hosts
$ cluster_reboot
bigpi1에서 HDFS 포맷 후 HDFS 서비스 시작 후 실행 중인 JAVA 가상 머신 확인

$ hdfs namenode -format -force
$ start-dfs.sh && start-yarn.sh
$ jps
bigpi1에서는 ResourceManager, NameNode, SecondaryNameNode, Jps 실행 중

bigpi2에서는 DataNode, NodeManager, Jps 실행 중
bigpi1에서 HDFS에 파일 저장 후 bigpi2에서 확인하기

pi@bigpi1:~$ hadoop fs -put $ HADOOP_HOME/README.txt /

pi@bigpi2:~$ hadoop fs -ls /
bigpi1에서 저장된 걸 bigpi2 에서 확인 가능
3. Spark 설정 및 실행
bigpi1에서 .bashrc 파일에 환경변수 추가

export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:$LD_LIBRARY_PATH
spark 설정 파일 작성

$ cd $SPARK_HOME/conf
$ sudo cp spark-defaults.conf.template spark-defaults.conf
$ sudo nano spark-defaults.conf

spark.master yarn
spark.driver.memory 465m
spark.yarn.am.memory 356m
spark.executor.memory 465m
spark.executor.cores 4
.bashrc 파일 적용 후 HDFS 재시작
$ cd ~
$ source .bashrc
$ stop-dfs.sh && stop-yarn.sh
$ start-dfs.sh && start-yarn.sh
$SPARK_HOME/examples/jars 디렉터리 하위 예제파일 확인 후 sparkpi 예제 실행

$ cd $SPARK_HOME/examples/jars
$ ls
$ spark-submit --deploy-mode client --class
org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-3.2.0.jar

Pi 근사값이 나온 것을 알 수 있다.
.bashrc 파일 내의 cluster_reboot, cluster_shutdown 함수 수정 및 서버 배포
$ cd
$ nano .bashrc

stop-yarn.sh && stop-dfs.sh &&
cluster_reboot 함수와 cluster_shutdown 함수 내부에 해당 내용을 맨 앞에 추가
수정된 .bashrc 파일 전체 서버에 배포하고 적용

$ cluster_scp ~/.bashrc
$ source .bashrc
$ cluster_reboot
HDSF 서비스가 먼저 종료함
'HDFS' 카테고리의 다른 글
| Sqoop (0) | 2021.12.22 |
|---|---|
| Apache Flume (0) | 2021.12.22 |
| Single Node 설정 (2) | 2021.12.20 |
| Cluster 설정 (0) | 2021.12.16 |
| 가상환경 설치(virtual hadoop cluster 구성) (0) | 2021.12.16 |



